My Portfolio
EPICOL18 - An interactive corpus-interface to an 18th century epistolary novels corpus

Epistolary Corpus of Long 18th Century Literature (EPICOL18) is now available with a corpus-interface programmed in Python and Dash that connects to a SQL Database of all texts. This EPICOL18 web-interface allows for advanced text search across a 4-million-word corpus. With features such as visualizing and downloading results as PNGs and CSVs, you can explore linguistic patterns in early modern epistolary fiction.
For a detailed documentation and description of the project, see here.
Libraries: dash, sqlite, html, css, wordcloud, spacy, nltk, pandas, regex
Dataset: collected by me, sources listed in the GitHub repository (see project link below)
Functions and Features
Landing Page
Description of the corpus and its features.

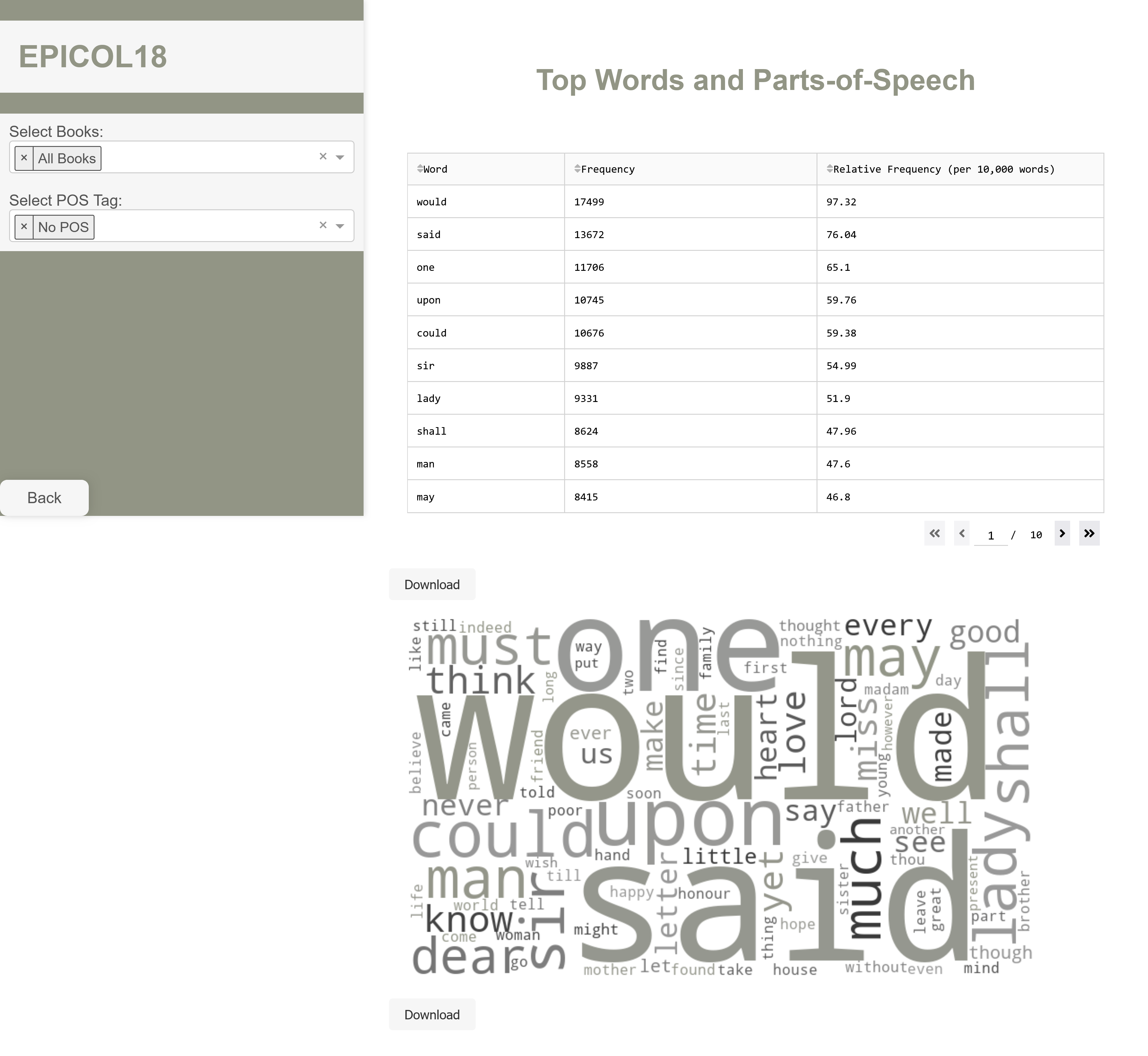
Top Words and Parts-of-Speech
Based on your text and POS-Tag selection, a table and word cloud with the top 100 key terms of the selected books and selected part-of-speech tag filter will be generated. Key words are the most frequent words excluding stopwords. The table displays the word, its raw frequency and its relative frequency in the selected books. The wordcloud visualizes these results with bigger words being more frequent than smaller words. You can either analyse word frequencies only, or filter them by their part-of-speech additionally. You can then choose to download the resulting Table as a CSV-file and the image as a PNG-file. As default option, the key terms calculated from all texts are displayed.
Key-Word-In-Context (KWIC)
Enter a search term using regular expressions [1] and search its appearanches across the entire corpus. By default, the text search is case-insensitive. The results are displayed in a column format with the left and right context of the search term next to the search term column. Further columns include the publication date and the book it appeared in. At the top, a total count of hits is displayed.

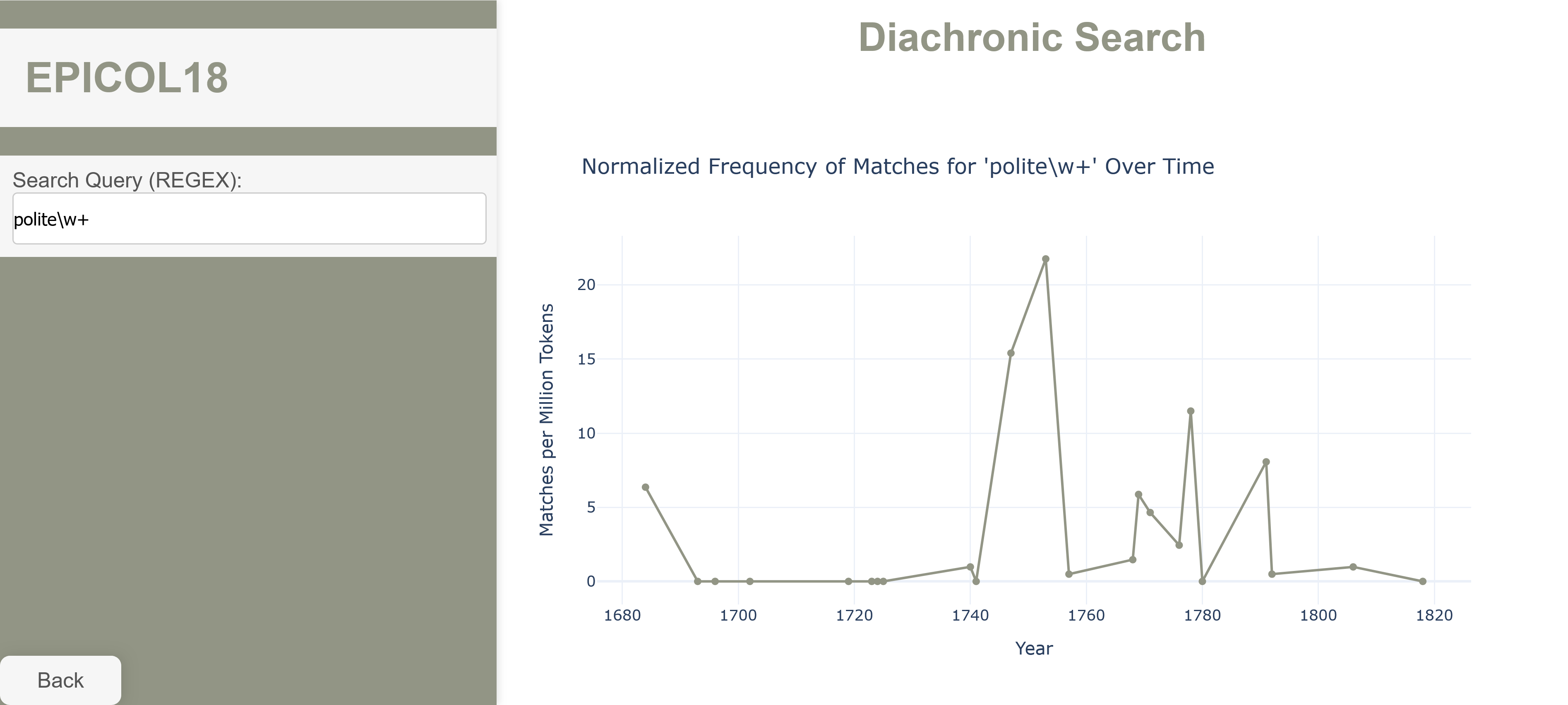
Diachronic Search
Enter a search term using regular expressions and visualize its frequencies across the entire corpus in a diachronic line chart. By default, the text search is case-sensitive. The years on the x-axis correspond to the publication dates of the books, the data points along the y-axis are accumulated frequences of the books in which the search term appears.
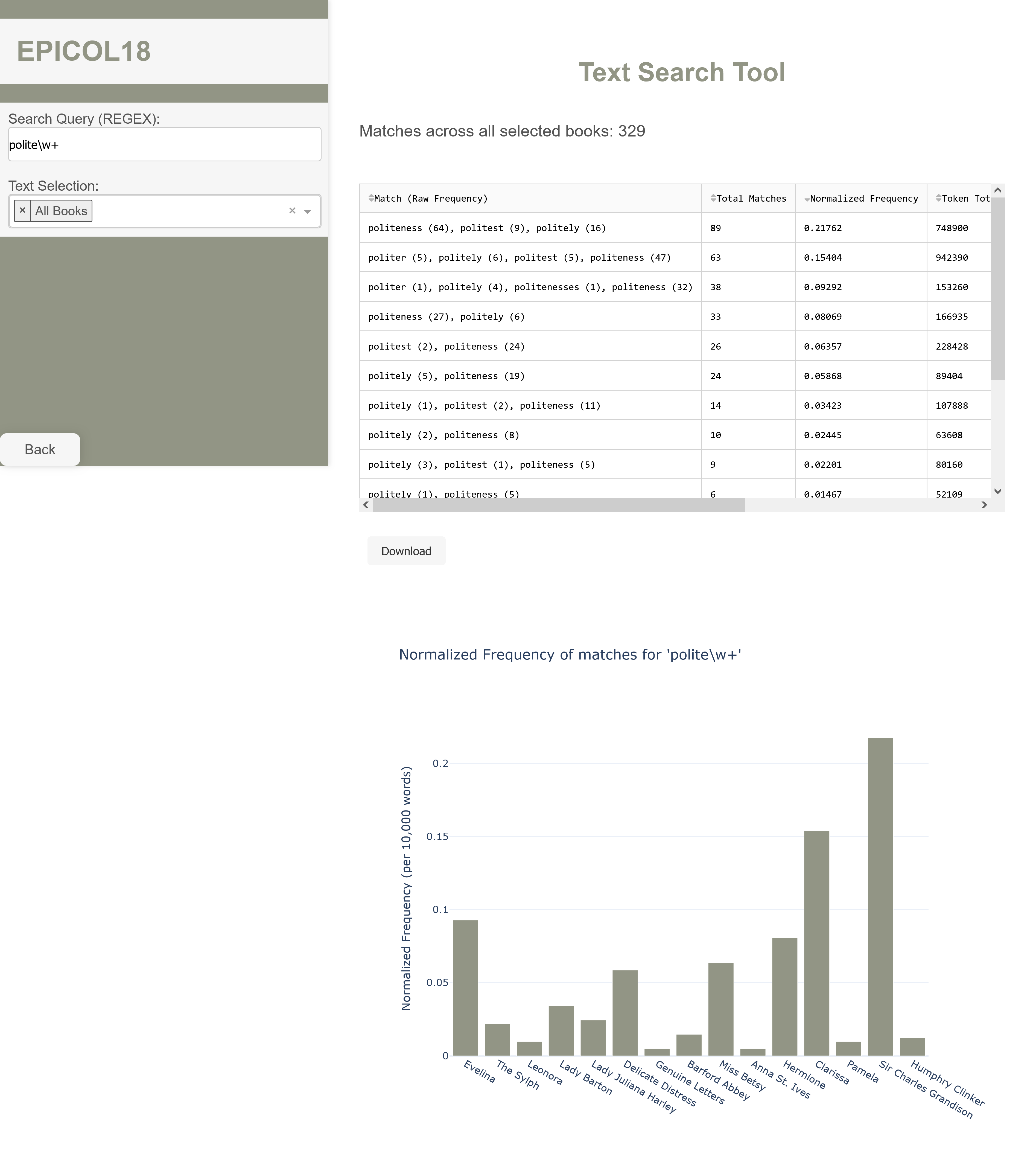
Text Search
Search for an individual word or phrase using regular expressions in a selection of texts. By default, the text search is case-sensitive. A table and bar chart are generated displaying the tokens that were matched with their raw frequencies in parenthesis, their sum, and normalized frequency with additional information on the size of the book, title, author, and publication year, where it was identified. The table is also downloadable as CSV-file. At the top, a total match count is displayed.
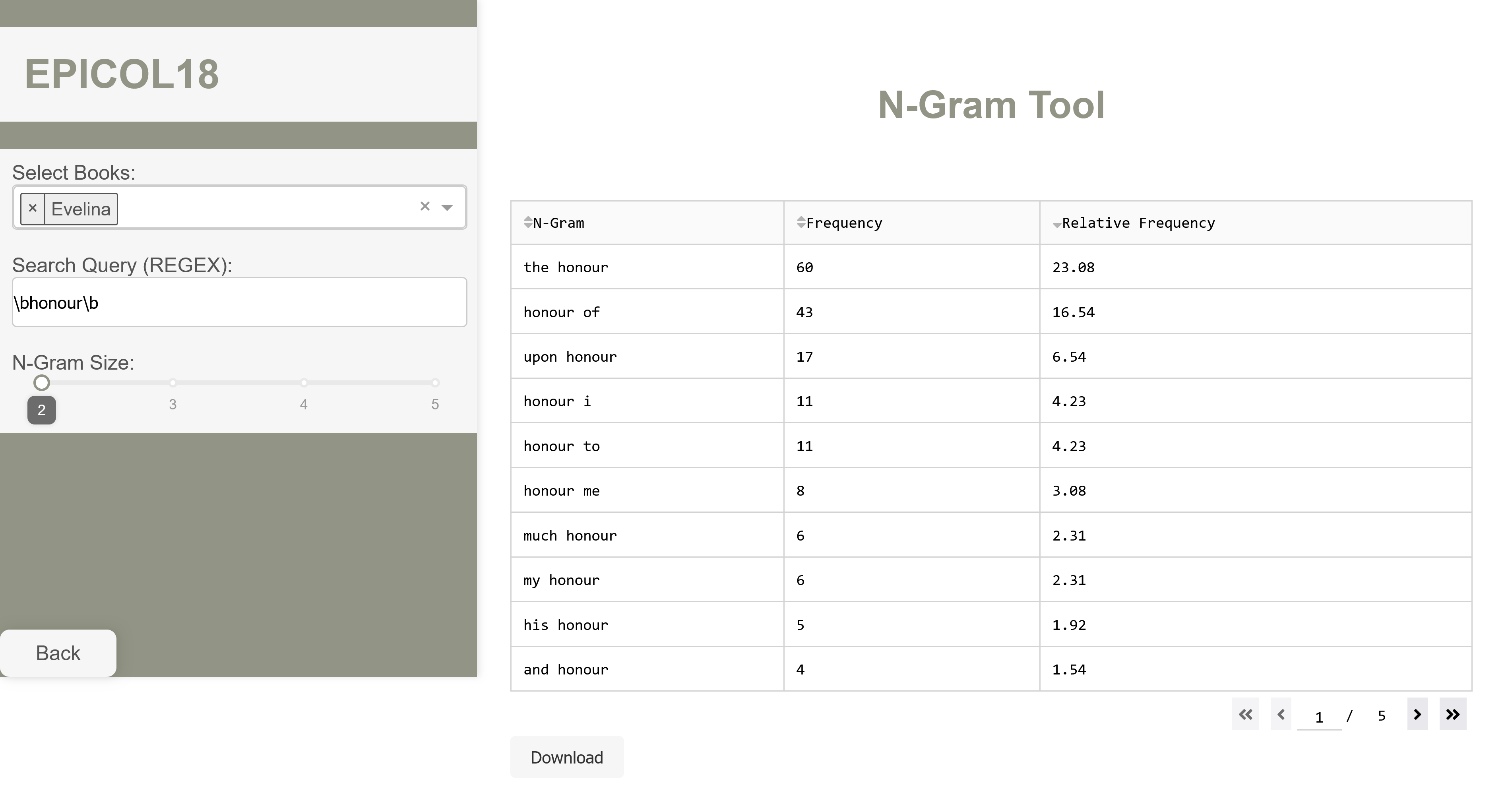
N-Grams
Based on your text selection and a search query formulated as regular expression, create word n-grams spanning two to five words and display their frequencies in a table with their raw and normalized frequencies. By default, the text search is case-insensitive, as all ngrams are lowercased.